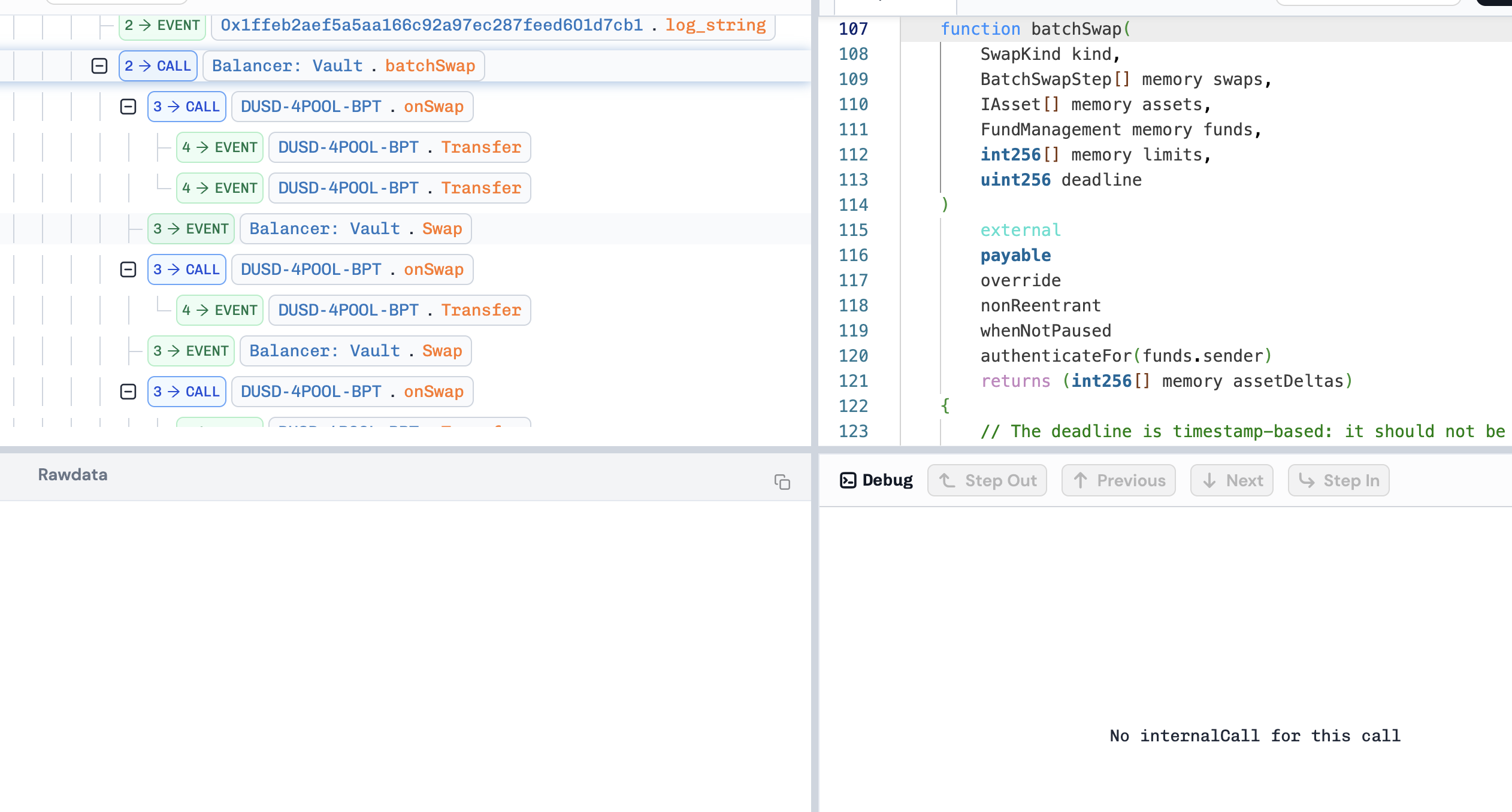
// Perform the swaps, updating the Pool token balances and computing the net Vault asset deltas. assetDeltas = _swapWithPools(swaps, assets, funds, kind);
// Process asset deltas, by either transferring assets from the sender (for positive deltas) or to the recipient // (for negative deltas). uint256 wrappedEth = 0; for (uint256 i = 0; i < assets.length; ++i) { IAsset asset = assets[i]; int256 delta = assetDeltas[i]; _require(delta <= limits[i], Errors.SWAP_LIMIT);
// These variables could be declared inside the loop, but that causes the compiler to allocate memory on each // loop iteration, increasing gas costs. BatchSwapStep memory batchSwapStep; IPoolSwapStructs.SwapRequest memory poolRequest;
// These store data about the previous swap here to implement multihop logic across swaps. IERC20 previousTokenCalculated; uint256 previousAmountCalculated;
for (uint256 i = 0; i < swaps.length; ++i) { batchSwapStep = swaps[i];
// Sentinel value for multihop logic if (batchSwapStep.amount == 0) { // When the amount given is zero, we use the calculated amount for the previous swap, as long as the // current swap's given token is the previous calculated token. This makes it possible to swap a // given amount of token A for token B, and then use the resulting token B amount to swap for token C. _require(i > 0, Errors.UNKNOWN_AMOUNT_IN_FIRST_SWAP); bool usingPreviousToken = previousTokenCalculated == _tokenGiven(kind, tokenIn, tokenOut); _require(usingPreviousToken, Errors.MALCONSTRUCTED_MULTIHOP_SWAP); batchSwapStep.amount = previousAmountCalculated; }
// Initializing each struct field one-by-one uses less gas than setting all at once poolRequest.poolId = batchSwapStep.poolId; poolRequest.kind = kind; poolRequest.tokenIn = tokenIn; poolRequest.tokenOut = tokenOut; poolRequest.amount = batchSwapStep.amount; poolRequest.userData = batchSwapStep.userData; poolRequest.from = funds.sender; poolRequest.to = funds.recipient; // The lastChangeBlock field is left uninitialized
function_swapWithPool(IPoolSwapStructs.SwapRequest memory request) private returns ( uint256 amountCalculated, uint256 amountIn, uint256 amountOut ) { // Get the calculated amount from the Pool and update its balances address pool = _getPoolAddress(request.poolId); PoolSpecialization specialization = _getPoolSpecialization(request.poolId);
// Perform the swap request callback, and compute the new balances for 'token in' and 'token out' after the swap amountCalculated = pool.onSwap(request, tokenInTotal, tokenOutTotal); (uint256 amountIn, uint256 amountOut) = _getAmounts(request.kind, request.amount, amountCalculated);
// We access both token indexes without checking existence, because we will do it manually immediately after. EnumerableMap.IERC20ToBytes32Map storage poolBalances = _generalPoolsBalances[request.poolId]; uint256 indexIn = poolBalances.unchecked_indexOf(request.tokenIn); uint256 indexOut = poolBalances.unchecked_indexOf(request.tokenOut);
if (indexIn == 0 || indexOut == 0) { // The tokens might not be registered because the Pool itself is not registered. We check this to provide a // more accurate revert reason. _ensureRegisteredPool(request.poolId); _revert(Errors.TOKEN_NOT_REGISTERED); }
// EnumerableMap stores indices *plus one* to use the zero index as a sentinel value - because these are valid, // we can undo this. indexIn -= 1; indexOut -= 1;
uint256 tokenAmount = poolBalances.length(); uint256[] memory currentBalances = new uint256[](tokenAmount);
request.lastChangeBlock = 0; for (uint256 i = 0; i < tokenAmount; i++) { // Because the iteration is bounded by `tokenAmount`, and no tokens are registered or deregistered here, we // know `i` is a valid token index and can use `unchecked_valueAt` to save storage reads. bytes32 balance = poolBalances.unchecked_valueAt(i);
if (i == indexIn) { tokenInBalance = balance; } elseif (i == indexOut) { tokenOutBalance = balance; } }
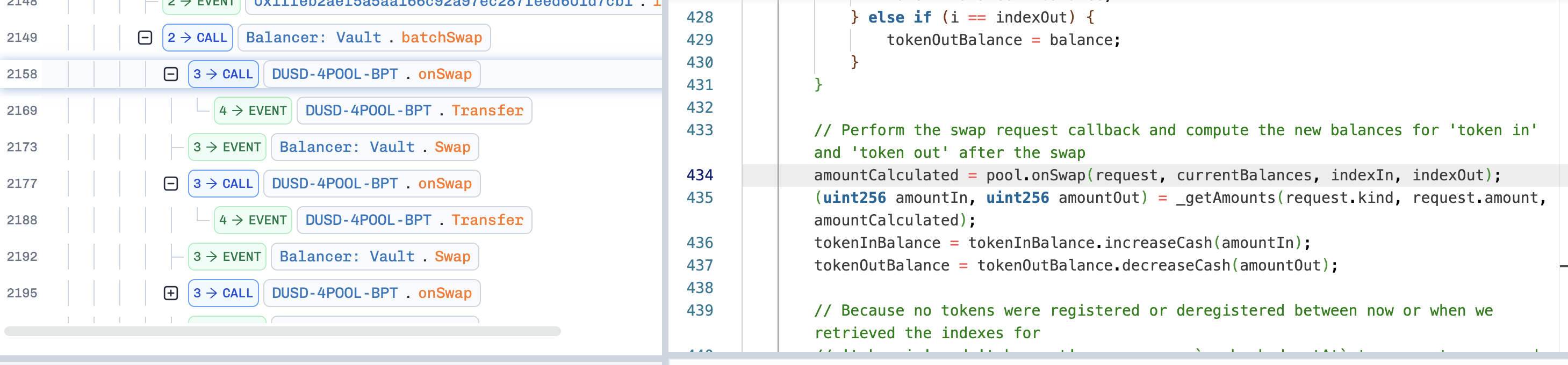
// Perform the swap request callback and compute the new balances for 'token in' and 'token out' after the swap amountCalculated = pool.onSwap(request, currentBalances, indexIn, indexOut); (uint256 amountIn, uint256 amountOut) = _getAmounts(request.kind, request.amount, amountCalculated); tokenInBalance = tokenInBalance.increaseCash(amountIn); tokenOutBalance = tokenOutBalance.decreaseCash(amountOut);
// Because no tokens were registered or deregistered between now or when we retrieved the indexes for // 'token in' and 'token out', we can use `unchecked_setAt` to save storage reads. poolBalances.unchecked_setAt(indexIn, tokenInBalance); poolBalances.unchecked_setAt(indexOut, tokenOutBalance); }
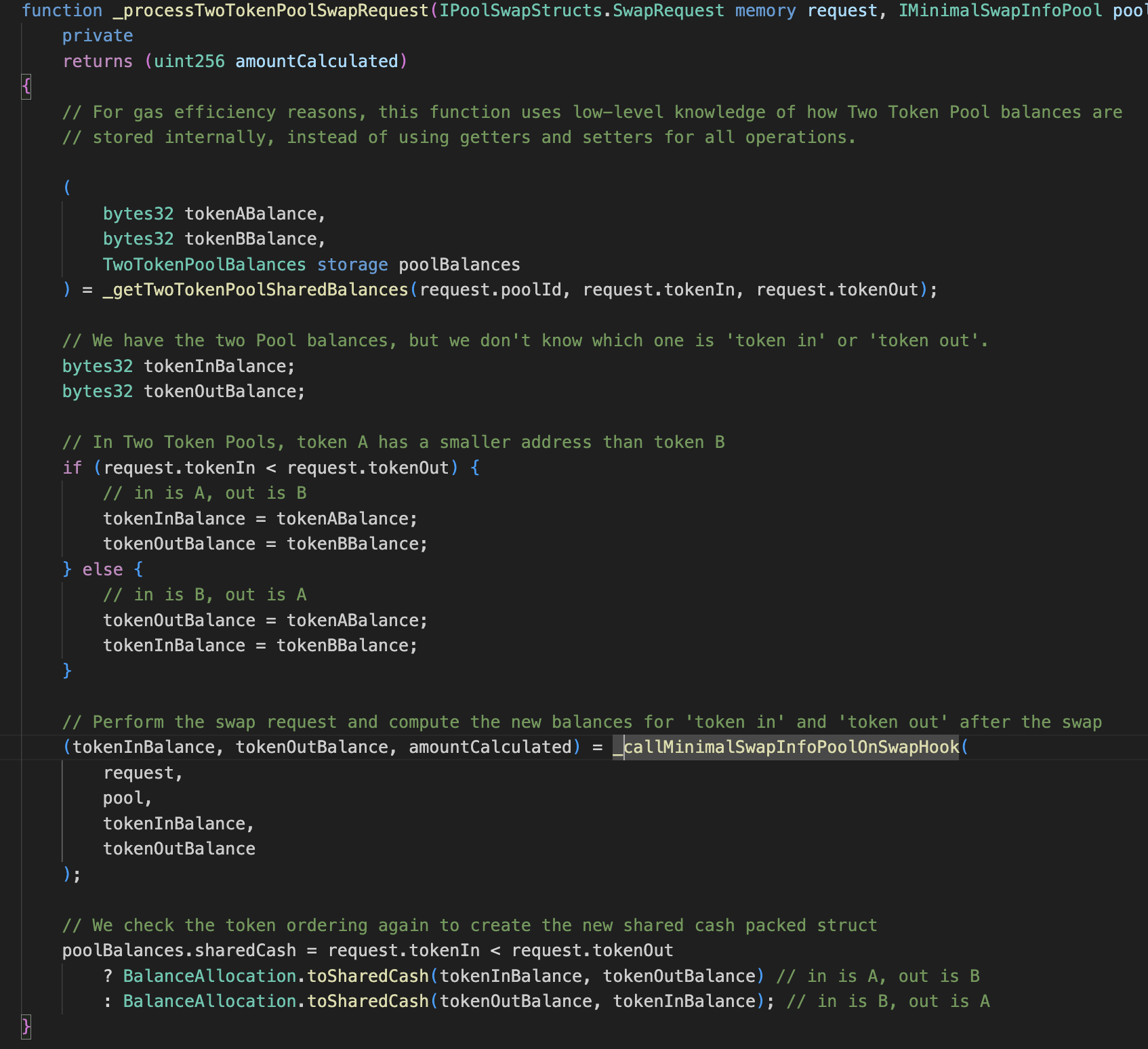
// Pools // // There are three specialization settings for Pools, which allow for cheaper swaps at the cost of reduced // functionality: // // - General: no specialization, suited for all Pools. IGeneralPool is used for swap request callbacks, passing the // balance of all tokens in the Pool. These Pools have the largest swap costs (because of the extra storage reads), // which increase with the number of registered tokens. // // - Minimal Swap Info: IMinimalSwapInfoPool is used instead of IGeneralPool, which saves gas by only passing the // balance of the two tokens involved in the swap. This is suitable for some pricing algorithms, like the weighted // constant product one popularized by Balancer V1. Swap costs are smaller compared to general Pools, and are // independent of the number of registered tokens. // // - Two Token: only allows two tokens to be registered. This achieves the lowest possible swap gas cost. Like // minimal swap info Pools, these are called via IMinimalSwapInfoPool.
1 2 3 4 5 6
// Perform the swap request callback and compute the new balances for 'token in' and 'token out' after the swap // 执行兑换请求回调,并计算兑换后“token in”和“token out”的新余额 amountCalculated = pool.onSwap(request, currentBalances, indexIn, indexOut); (uint256 amountIn, uint256 amountOut) = _getAmounts(request.kind, request.amount, amountCalculated); tokenInBalance = tokenInBalance.increaseCash(amountIn); tokenOutBalance = tokenOutBalance.decreaseCash(amountOut);
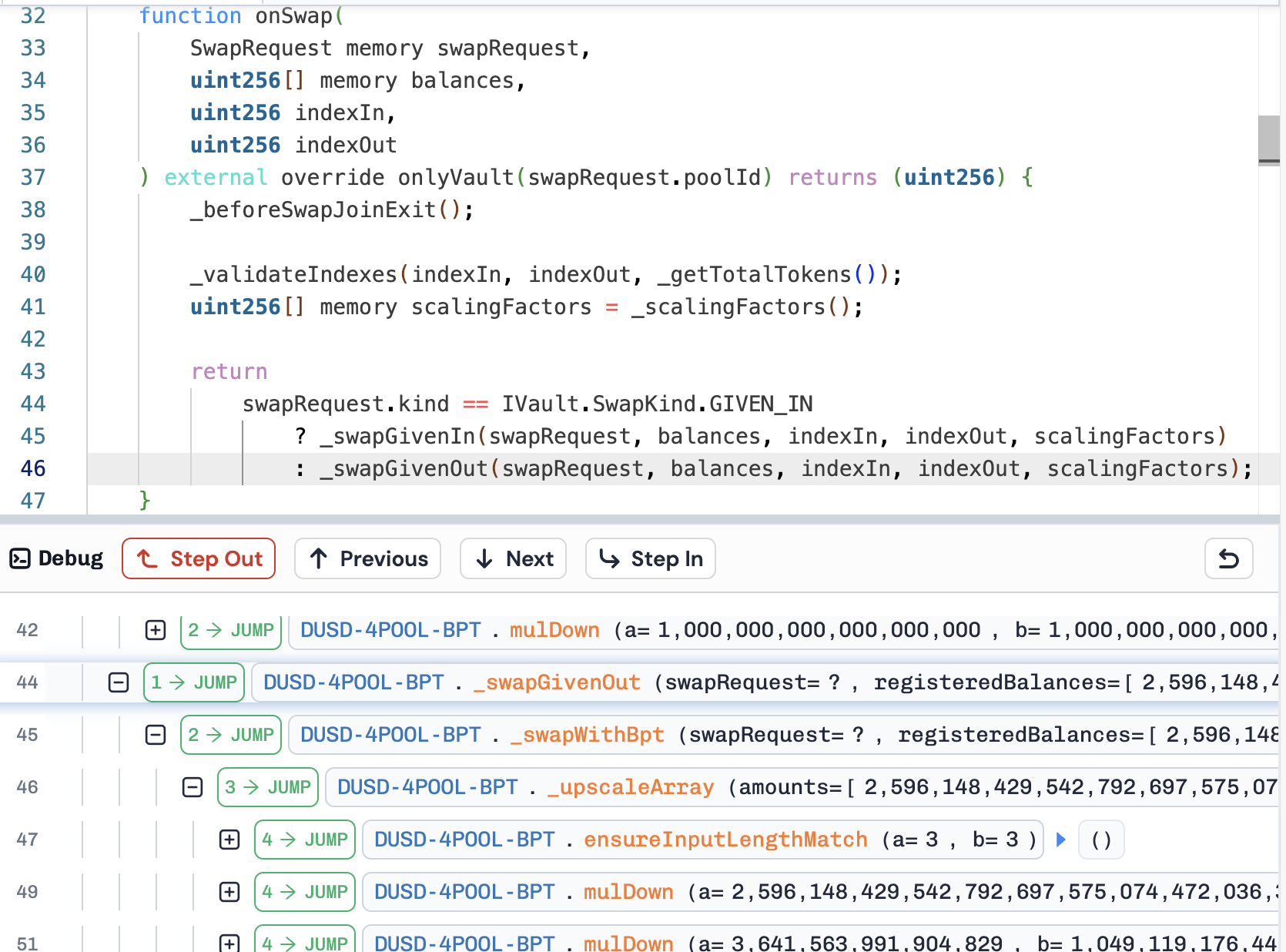
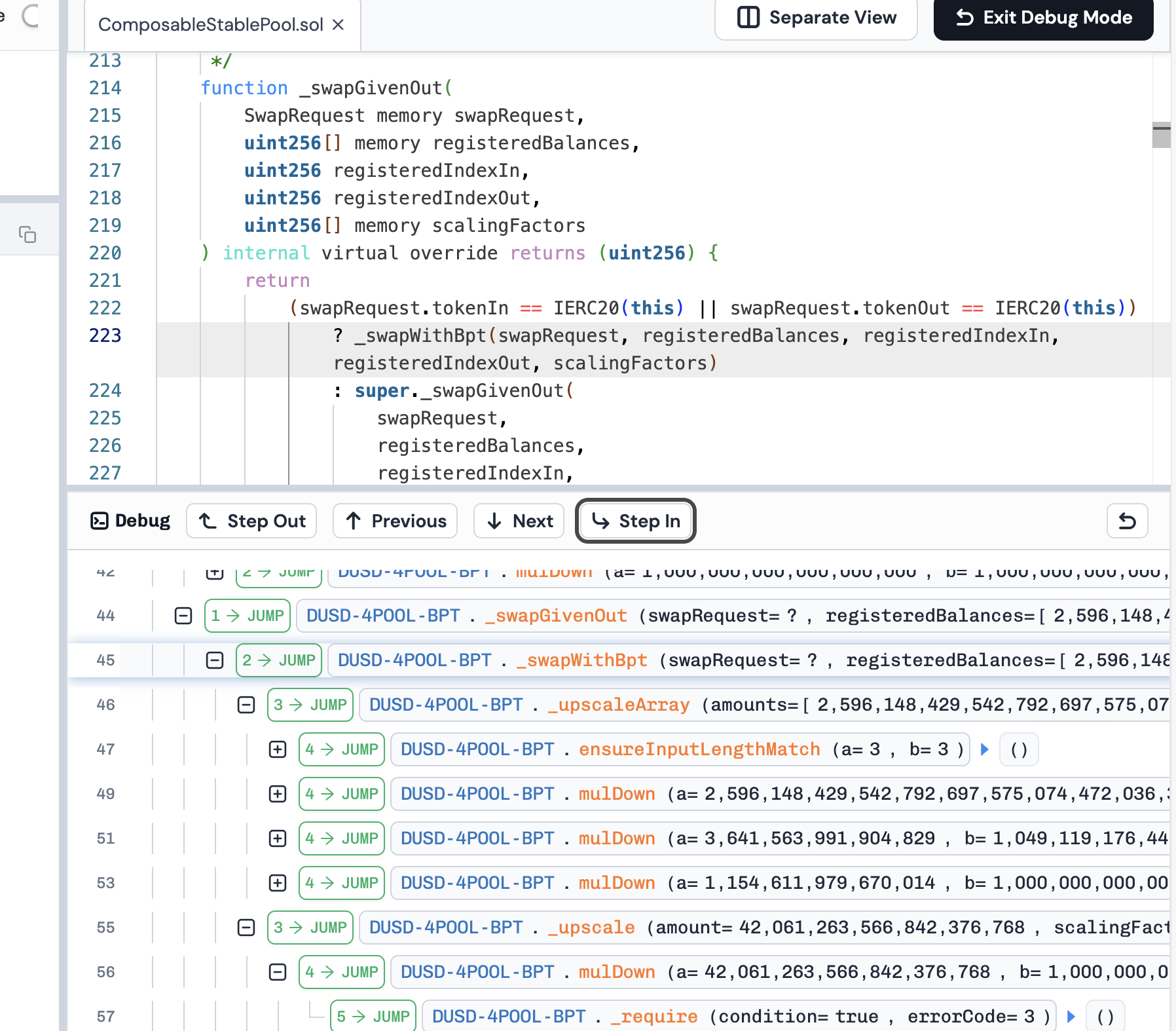
/** * @dev Override this hook called by the base class `onSwap`, to check whether we are doing a regular swap, * or a swap involving BPT, which is equivalent to a single token join or exit. Since one of the Pool's * tokens is the preminted BPT, we need to handle swaps where BPT is involved separately. * * At this point, the balances are unscaled. The indices and balances are coming from the Vault, so they * refer to the full set of registered tokens (including BPT). * * If this is a swap involving BPT, call `_swapWithBpt`, which computes the amountOut using the swapFeePercentage * and charges protocol fees, in the same manner as single token join/exits. Otherwise, perform the default * processing for a regular swap. */ function_swapGivenOut( SwapRequest memory swapRequest, uint256[] memory registeredBalances, uint256 registeredIndexIn, uint256 registeredIndexOut, uint256[] memory scalingFactors ) internal virtual override returns (uint256) { return (swapRequest.tokenIn == IERC20(this) || swapRequest.tokenOut == IERC20(this)) ? _swapWithBpt(swapRequest, registeredBalances, registeredIndexIn, registeredIndexOut, scalingFactors) : super._swapGivenOut( swapRequest, registeredBalances, registeredIndexIn, registeredIndexOut, scalingFactors ); }
/** * @dev Same as `_upscale`, but for an entire array. This function does not return anything, but instead *mutates* * the `amounts` array. */ function_upscaleArray(uint256[] memory amounts, uint256[] memory scalingFactors) internal pure { uint256 length = amounts.length; InputHelpers.ensureInputLengthMatch(length, scalingFactors.length);
for (uint256 i = 0; i < length; ++i) { amounts[i] = FixedPoint.mulDown(amounts[i], scalingFactors[i]); } }
functionmul(uint256 a, uint256 b) internal pure returns (uint256) { uint256 c = a * b; _require(a == 0 || c / a == b, Errors.MUL_OVERFLOW); return c; }
functionmulDown(uint256 a, uint256 b) internal pure returns (uint256) { uint256 product = a * b; _require(a == 0 || product / a == b, Errors.MUL_OVERFLOW);
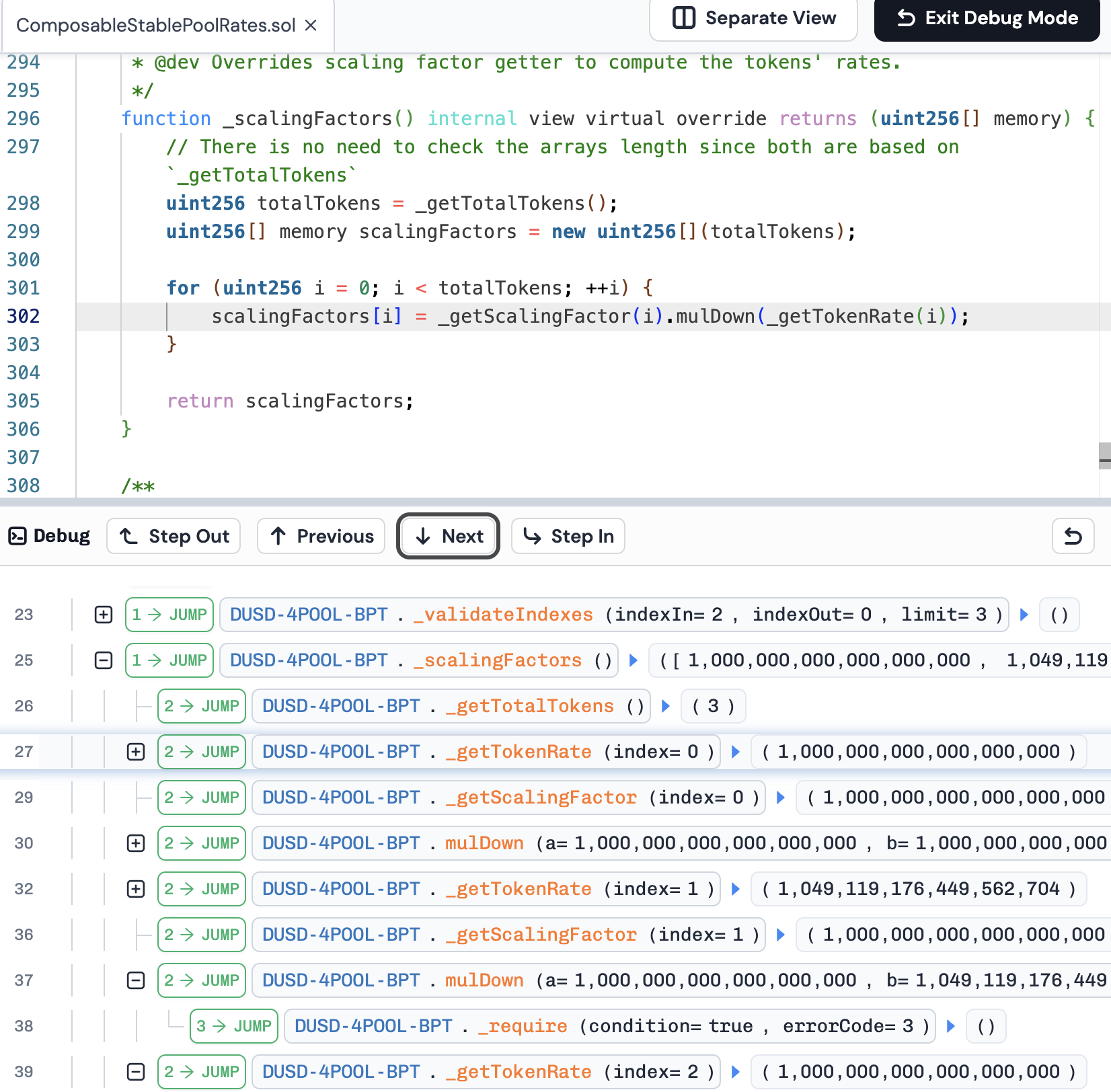
function_scalingFactors() internal view virtual override returns (uint256[] memory) { // There is no need to check the arrays length since both are based on `_getTotalTokens` uint256 totalTokens = _getTotalTokens(); uint256[] memory scalingFactors = new uint256[](totalTokens);
for (uint256 i = 0; i < totalTokens; ++i) { scalingFactors[i] = _getScalingFactor(i).mulDown(_getTokenRate(i)); }
// amountIn tokens are entering the Pool, so we round up. amountIn = _downscaleUp(amountIn, scalingFactors[indexIn]);
// Fees are added after scaling happens, to reduce the complexity of the rounding direction analysis. return_addSwapFeeAmount(amountIn); }
阶段 3:精确小额互换(触发精度损失)
1 2 3 4 5 6 7
function_upscale(uint256 amount, uint256 scalingFactor) internal pure returns (uint256) { // Upscale rounding wouldn't necessarily always go in the same direction: in a swap for example the balance of // token in should be rounded up, and that of token out rounded down. This is the only place where we round in // the same direction for all amounts, as the impact of this rounding is expected to be minimal (and there's no // rounding error unless `_scalingFactor()` is overriden). returnFixedPoint.mulDown(amount, scalingFactor); }
这里产生精度损失导致误差。
后续继续步入可以看到走到了_onRegularSwap函数中。由于上述的误差,所以导致计算出的不变值 D 被低估。
随后就是恢复流动性–重复导致误差积累越来越多–换回 BPT 并结算。
让AI总结一下:
关键代码位置总结
精度损失发生点:
_upscaleArray → FixedPoint.mulDown (余额缩放)
_upscale → FixedPoint.mulDown (金额缩放)
精度损失传递:
缩放后的余额 → StableMath._calculateInvariant → 不变值 D 被低估